leetcode刷题笔记
1.TwoSum
题目描述
题目描述:给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1]。
代码详解
解法:代码如下所示,此处展示的方法为哈希表法,相比于暴力双循环法,更快。
主要的思路便是将遍历的数字放入一个map或unordered_map的哈希表中,从哈希表中获取数据速度更快。
1 | class Solution{ |
注意点
- 将数值插入map利用的是
1
m.insert(make_pair(nums[i], i));
- 判断某个元素 x 是否存在于哈希表中利用的是
1
if(m.count(x)) //m.count(x)的返回值为元素x在容器m中出现的次数。
=========================================================================
2.AddTwoNummbers
题目描述
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例1:
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.
示例2:
输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9]
输出:[8,9,9,9,0,0,0,1]
代码详解
大概能想到两种思路
- 获取每个链表的数字,数字相加,再将结果放入链表中。但这种方式时间复杂度较高。
- 每一位的数字相加,如果有进位,利用carry记录进位。这方方式时间复杂度低。
详细代码如下
1 | //链表结点的声明方式 |
注意点
- 链表节点声明方式如下
1
2
3
4
5
6
7struct ListNode {
int val;
ListNode *next;
ListNode() : val(0), next(nullptr) {}
ListNode(int x) : val(x), next(nullptr) {}
ListNode(int x, ListNode *next) : val(x), next(next) {}
}; - 注意链表的用法,如何新加节点,如何获取结点的值,以及如何通过前一个结点,进入到下一个结点。
=========================================================================
3.LengthOfLongestSubstring
题目描述
找到字符串中最长的不重复的子字符串。
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
代码详解
寻找字符串中的子串,想到滑动窗口的方法
又因为强调的是无重复,所以想到hashmap的方法进行优化
详细的代码如下
1 | int lenghtOfLongestSubstring(stirng s){ |
注意点
- 记录字符的位置时,使用了,如下代码。这里记录的位置是 i+1 这样方便了后续的比较,更加贴合实际,实际的窗口起始边界一定是在窗口内第一个元素的左边。这样写极大的方便了后续计算长度的操作。
1
mp.insert(make_pair(s[i], i + 1));
- 向map数据结构中插入数值时,使用make_pair(a, b)的写法。
=========================================================================
4.findMedianSortedArrays
题目描述
找到两个排序数组的中位数
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
算法的时间复杂度应该为 O(log (m+n)) 。
示例 1:
输入:nums1 = [1,3], nums2 = [2]
输出:2.00000
解释:合并数组 = [1,2,3] ,中位数 2
示例 2:
输入:nums1 = [1,2], nums2 = [3,4]
输出:2.50000
解释:合并数组 = [1,2,3,4] ,中位数 (2 + 3) / 2 = 2.5
代码详解
能想到的方法有两种
一:暴力排序,使用一个set容器,将数据排序,然后从新求出中位数,但是时间复杂度过高,不符合要求(具体代码实现如下)。
1 | double findMedianSortedArray1(vector<int>& num1, vector<int>& num2){ |
二:二分法查找,由于两个数组长度已知,所以中位数在两个数组中的位置可以算出的。只需要维护两个指针,每次将较小的指针向后移动,直到一个指针到达中位数的位置。(代码实现如下)。
这个算法的主要思路:在两个有序数组中找到第K个元素,就可以通过比较两个数组中元素的大小,每次比较将其中一个较小的数组的指针后移,计数器加1,直到计数器的值 = K - 1时,此时中位数就是两个指针指向的较小值。
优化:虽然这个思路很好理解,但是依然有优化的空间,即直接从两个数组的[k/2 - 1]处的值开始比较,这样能极大的加快运行速度。优化的算法有一点绕,可以结合代码进行理解。实在不行就结合题解的图,进行理解。
1 | int getKthElement(vector<int>& nums1, vector<int>& nums2, int k){ |
注意点
在寻找第 k 小的数时,在getKthElement()中,利用Index1,Index2两个变量记录已经删去的元素的个数,用newIndex1,newIndex2记录本次循环后,新的删去元素的个数。因此,每次循环之后都要更新index的值,以及更新K的值(这里K代表的是当前数组中第K小的值,由于不断删除中位数左侧的值,所以K的值也要不断减小)
1
2
3
4
5
6
7
8if(pivot1 <= pivot2){
k -= newIndex1 - index1 + 1; //更新k值,从寻找第k小的数,更新为寻找第(k - 本次循环删除元素的个数)小的数
index1 = newIndex1 + 1; //删除的个数为下标值 + 1
}
else{
k -= newIndex2 - index2 + 1; //更新k值,从寻找第k小的数,更新为寻找第(k - 本次循环删除元素的个数)小的数
index2 = newIndex2 + 1; //删除的个数为下标值 + 1
}注意循环的停止条件,当K=1时,可以停止。当其中一个数组全部删除时,可以停止。
1
2
3
4
5
6
7
8
9
10if(index1 == m){
return nums2[index2 + k - 1]; //当其中一个数组到达边界值时,可以直接返回中位数
}
if(index2 == n){
return nums1[index1 + k - 1]; //同上
}
if(k == 1){
return min(nums1[index1], nums2[index2]);
//当k值变化到1时,比较此时两个数组中更新后的值的大小,小的一方为中位数
}最后,当两个数组元素的个数为偶数时,在平均值计算时,需要 / 2.0 将结果转化为double型。
1
return (getKthElement(nums1, nums2, n / 2) + getKthElement(nums1, nums2, n / 2 + 1)) / 2.0;
=========================================================================
5.longestPalindrome
题目描述
给你一个字符串 s,找到 s 中最长的回文子串。
示例 1:
输入:s = “babad”
输出:”bab”
解释:”aba” 同样是符合题意的答案。
示例 2:
输入:s = “cbbd”
输出:”bb”
代码详解
关于回文串的问题,有许多方法,在这儿先介绍这题的其中一个方法,叫做中心扩展算法。这种方法用时短,内存占用少,比较推荐。
中心扩展算法的本质即使,枚举所有回文中心,并尝试扩展,直到无法继续扩展为止。在枚举过程中记录长度的最大值和最大值时的回文中心。这样我们首先需要一个函数计算一个回文中心的回文串长度,通过比较长度,找出最长的回文串。因为回文串有单数和偶数两种,所以设置了两个回文中心值,单数时让左右值相等即可
1 | int expandAroundCenter(const string& s, int left, int right){ |
寻找最长回文串的代码如下
1 | string longestPalindrome2(string s){ |
注意点
- 在枚举回文中心时,要同时考虑到奇数和偶数回文串的情况,因此计算了两个回文串的长度,并记录了最长的情况。
1
2
3int l1 = expandAroundCenter(s, i, i);
int l2 = expandAroundCenter(s, i, i + 1);
int l = max(l1, l2); - 奇数回文串和偶数回文串,在计算其实位置时,稍有不同,需要注意。
1
2begin = i - l/2; //奇数
begin = i - l/2 + 1;//偶数
=========================================================================
7.reverse
题目描述
给你一个 32 位的有符号整数 x ,返回将 x 中的数字部分反转后的结果。
如果反转后整数超过 32 位的有符号整数的范围 [−2^31, 2^31 − 1] ,就返回 0。
假设环境不允许存储 64 位整数(有符号或无符号)。
示例 1:
输入:x = 123
输出:321
示例 3:
输入:x = 120
输出:21
代码详解
这是一道比较经典的数字翻转问题,可以利用纯数组的方式弹出和推入数字。
1 | //弹出X末尾的数字,用digit接收。 |
上面的代码就是将末尾数字取出,并推入到输出值的末尾的方式,这样不仅快,而且节省空间。
整体代码如下
1 | int reverse(int x){ |
注意点
- 由于环境中不允许64位的数据出现,所以在判断是否超出范围时,由于rev不可能小于INT_MIN,不可能大于INT_MAX,所以选择将在更新rev之前,比较rev和INT_MIN / 10,或rev和INT_MAX / 10的大小。
1
if(rev < INT_MIN / 10 || rev > INT_MAX / 10)
=========================================================================
8.myAtoi(字符串转换整数)
题目描述
手动实现C++库中的atoi函数,将传入的字符串中的数字提取出来。
- 读入字符串并丢弃无用的前导空格。
- 读入下一个字符,直到到达下一个非数字字符或到达输入的结尾。字符串的其余部分将被忽略。
- 读取数字之前的正负号,负号为负。
- 如果整数超过32位有符号整数,需要截断这个这个数
代码详解
方法一:根据题意解题
明确转化规则
- 空格处理(一般要跳过)
- 正负号的处理
- 数字的处理
- 注意溢出
详细代码如下注意:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26int myAtoi(string s){
int res = 0;
int sign = 1;
int i = 0;
while(s[i] == ' '){
i++; //当遇到空格时,跳过
}
if(s[i] == '-'){
sign = -1;
i++;
}
else if(s[i] == '+'){
sign = 1;
i++;
}
while(i < s.length() && isdigit(s[i])){
int n = s[i] - '0';
//注意这里的判断是否溢出的逻辑
if(res > INT_MAX / 10 || (res == INT_MAX / 10 && n > 7)){
return sign > 0 ? INT_MAX : INT_MIN;
}
res = res * 10 + n;
i++;
}
return sign * res;
} - 明确转化时的规则,理清规则后,代码更容易编写。
- 这道题中,判断是否溢出的逻辑与第7题的有不同,第七题中由于输入值就不会超过32位整数的范围,所以可以通过第7题的判断逻辑,判断是否溢出。但这道题中输入值有超过32位整数范围的可能性,判断逻辑就要发生变化。注意INT_MAX = 2147483647,INT_MIN = -INT_MAX - 1 = -2147483648。这时的判断逻辑写法如下。
1
if(res > INT_MAX / 10 || (res == INT_MAX / 10 && n > 7)){}
方法二:自动机
这个题不难,但是为了防止写出臃肿的代码,比较好的方法是使用自动机的概念。即程序在每个时刻都有一个状态,这个状态记为a,从字符串中输出一个字符c,根据c转移到下一个状态a1。图示如下。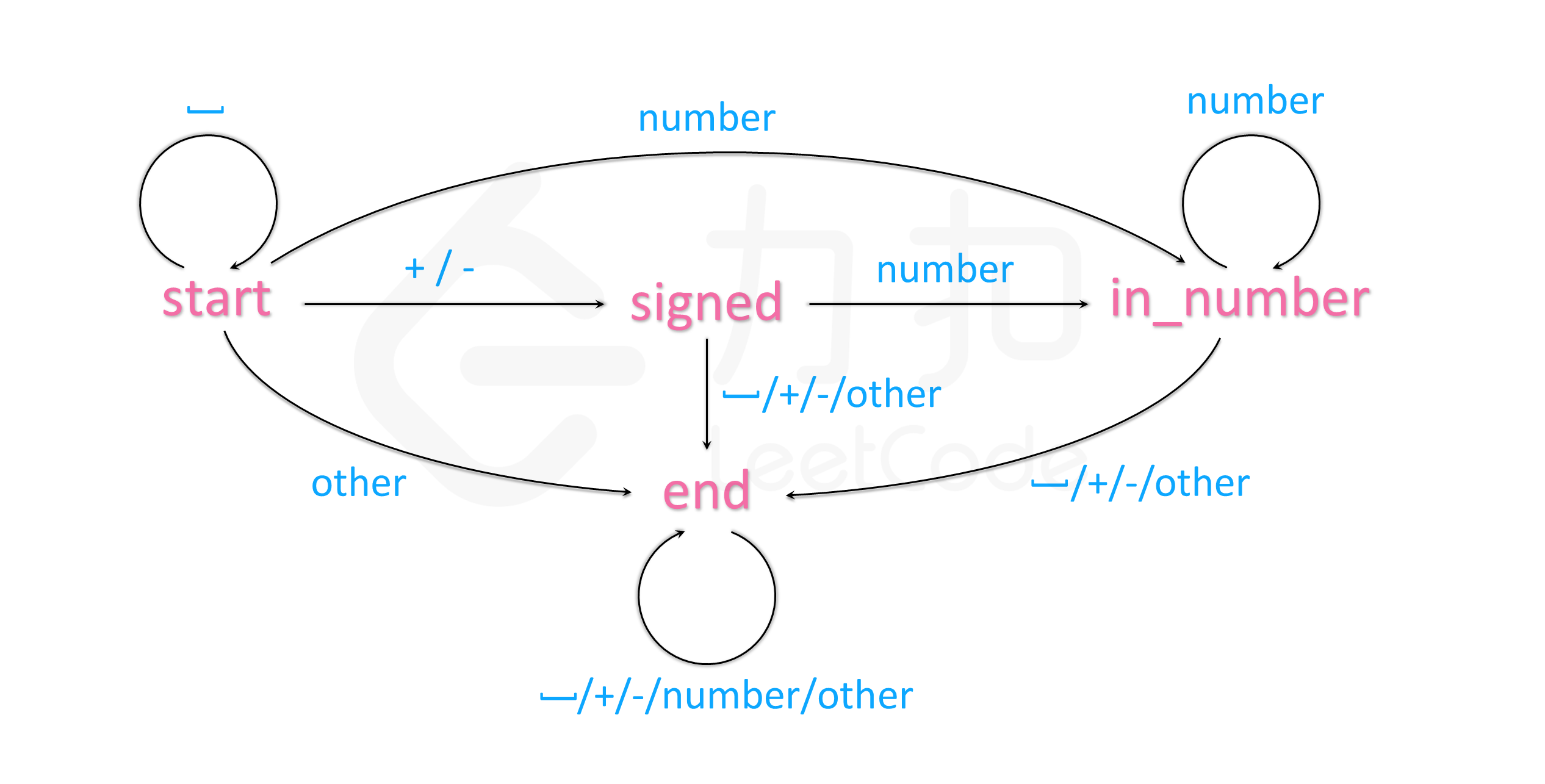
当前状态有四种,分别是“start”,“signed”,“in_number”,“end”。根据当前状态,和下一个读入的字符,可以获取下一阶段的状态。
比如当前状态是“start”,下一个读取的字符有四种可能,空格“ ”,正负号“+-”,数字“in_number”,其他字符“other”,这四种可能的字符,分别对应了下一阶段的状态,即下表中对应的四种状态。再比如当前状态为数字“in_number”,那么根据下一个读入的字符,对应的下一阶段的状态只有两种,当下一个字符是空格“ ”,正负号“+-”或其他“other”时,下一阶段的状态为“end”,即结束状态,只有当下一个字符也是数字“in_number”时,才会继续进行程序。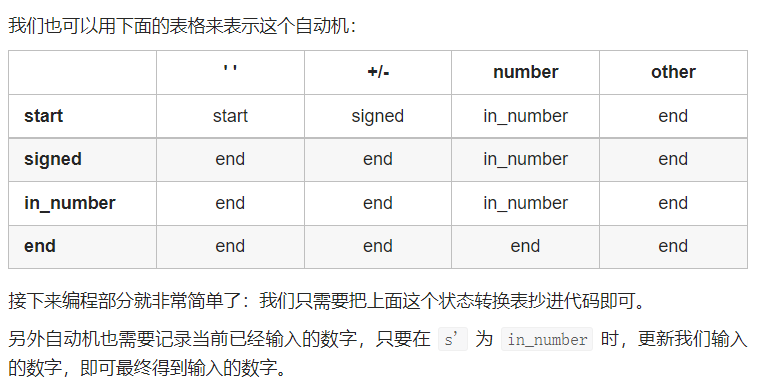
自动机实现代码如下。
1 | //首先创建一个自动机类 |
这两种方法都需要了解,相比之下,自动机写出的代码比较简洁,但是只要思路清晰,第一种方法有很大的优势,写出来的代码也同样可以很简洁。
注意点
- 要注意理解自动机的概念,在具体的使用过程中,需要结合实际情况进行代码方面的修改。
- 注意这两种代码中,判断是否溢出的方法。第一种判断方法使用的是int型数据的判断逻辑;第二种方法用的是long型数据的判断逻辑。两种判断逻辑在写法上有不同,需要注意。方法一中,都是int型数据,所以在判断时,用INT_MAX / 10,以及最后的个位数是否大于7,来判断最终的结果是否溢出。方法二中的ans为long型整数,所以判断时,选择将INT_MAX,INT_MIN转换成long型,再进行判断。
1
2
3
4//方法一:
if(res > INT_MAX / 10 || (res == INT_MAX / 10 && n > 7)){
return sign > 0 ? INT_MAX : INT_MIN;
}1
2
3
4
5
6
7
8//方法二:
if(sign == 1){
//ans为long型整数
ans = min(ans, (long)INT_MAX);
}
else{
ans = min(ans, -(long)INT_MIN);
}
=========================================================================
9.isPalindrome(回文数)
题目描述
给你一个整数 x ,如果 x 是一个回文整数,返回 true ;否则,返回 false。
回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。
示例 1:
输入:x = -121
输出:false
解释:从左向右读, 为 -121 。 从右向左读, 为 121- 。因此它不是一个回文数。
示例 2:
输入:x = 10
输出:false
解释:从右向左读, 为 01 。因此它不是一个回文数。
代码详解
这道题比较基础,写法与之前的将一个数字翻转几乎相同,这里给出时间复杂度最小的一种写法,因为是判断回文数,所以只需要翻转一半的数字即可
1 | bool isPalindrome(int x){ |
注意点
- 对于121型回文数,会出现reverseNum = 12,x = 1的情况,这时,reverseNum / 10 == x即可。
=========================================================================
10.isMatch(正则表达式匹配)
题目描述
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 ‘.’ 和 ‘‘ 的正则表达式匹配。
‘.’ 匹配任意单个字符
‘‘ 匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。
示例 1:
输入:s = “aa”, p = “a”
输出:false
解释:”a” 无法匹配 “aa” 整个字符串。
示例 2:
输入:s = “aa”, p = “a*”
输出:true
解释:因为 ‘*’ 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 ‘a’。因此,字符串 “aa” 可被视为 ‘a’ 重复了一次。
示例 3:
输入:s = “ab”, p = “.“
输出:true
解释:”.“ 表示可匹配零个或多个(’*’)任意字符(’.’)。
代码详解
这道题是(hard),比较难的一道题。
1 | /* |